
Recommandé
Recommandé
Contenu connexe
Tendances
Tendances (20)
En vedette
En vedette (16)
Similaire à Tối ưu-cau-lệnh-oracle-sql
Similaire à Tối ưu-cau-lệnh-oracle-sql (20)
Tối ưu-cau-lệnh-oracle-sql
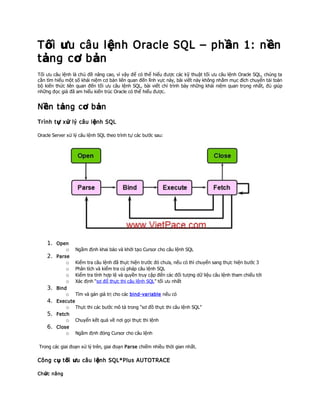
- 1. T ối ưu câu l ệnh Oracle SQL – ph ần 1: n ền t ảng c ơ b ản Tối ưu câu lệnh là chủ đề nâng cao, vì vậy để có thể hiểu được các kỹ thuật tối ưu câu lệnh Oracle SQL, chúng ta cần tìm hiểu một số khái niệm cơ bản liên quan đến lĩnh vực này, bài viết này không nhằm mục đích chuyển tải toàn bộ kiến thức liên quan đến tối ưu câu lệnh SQL, bài viết chỉ trình bày những khái niệm quan trọng nhất, đủ giúp những đọc giả đã am hiểu kiến trúc Oracle có thể hiểu được. N ền t ảng c ơ b ản Trình t ự x ử lý câu l ệnh SQL Oracle Server xử lý câu lệnh SQL theo trình tự các bước sau: 1. Open o Ngầm định khai báo và khởi tạo Cursor cho câu lệnh SQL 2. Parse o Kiểm tra câu lệnh đã thực hiện trước đó chưa, nếu có thì chuyển sang thực hiện bước 3 o Phân tích và kiểm tra cú pháp câu lệnh SQL o Kiểm tra tính hợp lệ và quyền truy cập đến các đối tượng dữ liệu câu lệnh tham chiếu tới o Xác định “sơ đổ thực thi câu lệnh SQL” tối ưu nhất 3. Bind o Tìm và gán giá trị cho các bind-variable nếu có 4. Execute o Thực thi các bước mô tả trong “sơ đồ thực thi câu lệnh SQL” 5. Fetch o Chuyển kết quả về nơi gọi thực thi lệnh 6. Close o Ngầm định đóng Cursor cho câu lệnh Trong các giai đoạn xử lý trên, giai đoạn Parse chiếm nhiều thời gian nhất. Công c ụ t ối ưu câu l ệnh SQL*Plus AUTOTRACE Ch ức năng
- 2. Thu thập thông tin mô tả quá trình thực thi câu lệnh SQL, thường được dùng để tối ưu câu lệnh. Cài đ ặt Để sử dụng đầy đủ chức năng của công cụ này, cần tạo Table tên PLAN_TABLE và gán nhóm quyền PLUSTRACE cho tài khoản muốn sử dụng công cụ: 1. Dùng $ORACLE_HOME/rdbms/admin/utlxplan.sql để tạo PLAN_TABLE 2. Dùng tài khoản DBA chạy mã lệnh $ORACLE_HOME/sqlplus/admin/plustrce.sql để tạo nhóm quyền PLUSTRACE. Ví dụ Quan sát kết quả từ mã dẫn trên, ta thấy công cụ AUTOTRACE gửi về ba nhóm thông tin sau: 1. Kết quả câu lệnh 2. Sơ đồ trình tự thực thi câu lệnh 3. Thông tin thống kê chi phí tài nguyên cần dùng để thực thi câu lệnh Cách s ử d ụng
- 3. Cú pháp l ệnh Ý nghĩa SET AUTOTRACE ON Bật tính năng thu thập và hiển thị thông tin đầy đủ SET AUTOTRACE OFF Tắt tính năng thu thập và hiển thị thông tin SET AUTOTRACE ON EXPLAIN Hiển thị kết quả và EP câu lệnh SET AUTOTRACE ON STATISTICS Hiển thị kết quả và thông tin thống kê câu lệnh SET AUTOTRACE TRACEONLY Hiển thị EP và thông tin thống kê, không hiển thị kết quả câu lệnh SET AUTOTRACE TRACEONLY EXPLAIN Chỉ hiển thị EP SET AUTOTRACE TRACEONLY STATISTICS Chỉ hiển thị thống kê S ơ đ ồ th ực thi câu l ệnh SQL Sơ đồ thực thi câu lệnh SQL (Execution Plan - EP) mô tả thứ tự các bước Oracle cần thực thi để có được kết quả câu lệnh nhanh nhất. Ví dụ về EP của câu lệnh xem dữ liệu trên hai Table CUSTOMERS và COUNTRIES: Oracle qui định thứ tự xử lý các bước của EP như sau: 1. Bắt đầu xử lý từ bước nằm thụt về phía bên phải nhất, tiếp theo là các bước đứng kế trước nó 2. Nếu hai bước có cùng thứ tự thì sẽ xử lý bước nằm phía trên trước Như vậy, ta thấy EP trên được xử lý theo thứ tự được đánh số bên phải. Một EP đầy đủ bao gồm ba thành tố sau: phương thức truy cập dữ liệu, phương pháp JOIN và thứ tự JOIN giữa hai hay nhiều tập dữ liệu. Ph ương th ức truy c ập d ữ li ệu
- 4. Xác định cách thức truy cập vật lý đến từng dòng dữ liệu của Table, ví du một số phương pháp truy cập dữ liệu Table phổ biến: • Truy cập theo cách đọc từng dòng của Table ( TABLE ACCESS (FULL) ): đọc toàn bộ dòng dữ liệu của Table để đối sánh dữ liệu, vì vậy nếu Table có kích thước lớn thì phương thức truy cập này sẽ chiếm nhiều chi phí IO. Tuy nhiên, cách truy cập này cho phép chúng ta có thể cấu hình đọc nhiều khối dữ liệu (Block) cho một thao tác đọc và nhiều tiến trình cùng đọc một lúc. • Truy cập dữ liệu cây Index (INDEX SCAN): duyệt cây Index theo giá trị khóa cần tìm, kết quả tìm được có lưu giá trị ROWID của dòng dữ liệu chứa giá trị khóa • Truy cập dữ liệu Table theo Index ( TABLE ACCESS (BY INDEX ROWID)): phương thức truy cập này bao gồm hai bước tách biệt: 1. Duyệt cây Index để tìm ROWID tương ứng với giá trị khóa 2. Đọc dòng dữ liệu của Table theo ROWID tìm được một cách nhanh nhất Với cách này, ta thấy để đọc được một dòng dữ liệu của Table thì phải tốn ít nhất hai thao tác IO; một thao tác IO đọc trên cây Index và một thao tác IO đọc trên Table. Theo luật chung thì cách này thích hợp khi kết quả dữ liệu cần tìm ít hơn 5% khối lượng dữ liệu của Table. Ph ương pháp JOIN Xác định phương pháp kết hợp dữ liệu giữa hai hay nhiều Table với nhau, ví dụ về phương pháp JOIN giữa hai Table T1 và T2: 1. NESTED LOOP JOIN: với T1 là outer-table, T2 là inner-table thì từng dòng dữ liệu của Table T1 sẽ kết hợp so sánh với tất cả dòng dữ liệu của Table T2, kết quả trả về là tất cả các dòng dữ liệu thỏa điều kiện so sánh. 2. SORT MERGE JOIN: tập dòng dữ liệu của hai Table được sắp theo thứ tự trước khi ứng dụng thuật toán trộn trên chúng. Th ứ t ự JOIN Xác định thứ tự JOIN khi câu lệnh SQL có nhiều hơn hai Table kết hợp với nhau, thứ tự JOIN hợp lý giúp giảm thiểu dữ liệu cần kết hợp với nhau mà vẫn đạt được kết quả đúng. Sau khi tìm hiểu qua các khái niệm cơ bản, chúng ta thử quay lại tìm hiểu ý nghĩa EP của câu lệnh SQL trên: 1. Oracle chọn phương pháp JOIN là NESTED LOOP để thực hiện phép JOIN giữa hai Table. 2. Oracle chọn CUSTOMERS đóng vai trò là outer-table, COUNTRIES là inner-table 3. Bắt đầu đọc từng dòng dữ liệu của CUSTOMERS rồi so trùng với tất cả dòng của COUNTRIES, điểm lưu ý là giá trị COUNTRIES.COUNTRY_ID này được lấy từ cây Index COUNTRY_PK 4. Kết quả trả về là tất cả những dòng dữ liệu thỏa điều kiện so trùng Đến đây có thể các bạn thắc mắc là tại sao Oracle lại chọn phương pháp Join là NESTED LOOP ? tại sao CUSTOMERS lại được chọn làm outer-table ?, quyết định chọn này được thực hiện bởi Trình tối ưu câu lệnh Oracle.
- 5. Trình t ối ưu câu l ệnh Oracle Trình tối ưu giúp Oracle xác định được một EP tốt nhất cho một câu lệnh SQL. Trình tối ưu Oracle 9i hỗ trợ phương pháp tối ưu dựa vào cú pháp lệnh (Rule Based Optimizer – RBO) và phương pháp tối ưu dựa vào chi phí ước tính cần dùng để thực thi câu lệnh (Cost Based Optimizer – CBO). Mặc định Oracle9i dùng RBO. RBO RBO có từ phiên bản Oracle6, dựa vào cấu trúc câu lệnh SQL để xác định EP tốt nhất. RBO sử dụng một lược đồ phân hạng các phương thức truy cập dữ liệu để chọn phương thức truy cập cho EP, phương thức nào có số hạng thấp sẽ được ưu tiên chọn. Lược đồ phân hạng các phương thức truy cập dữ liệu được qui định như sau: Ta thấy truy cập theo ROWID có số hạng thấp nhất là 1; nghĩa là phương thức truy cập đến dữ liệu nhanh nhất, và truy cập theo Index có số hạng là 4 sẽ nhanh hơn nhiều so với truy cập theo Full-Table-Scan có số hạng cao nhất là 15. Ví dụ sau cho thấy RBO sử dụng luật phân hạng để chọn phương thức truy cập dữ liệu cho EP. Do cột CUST_ID của điều kiện WHERE có UNIQUE INDEX lên RBO chọn phương thức truy cập theo Index: SQL> DROP TABLE new_table; Table dropped. SQL> CREATE TABLE new_table AS SELECT object_id, object_name, object_type FROM all_objects WHERE rownum <= 5000; 2 3 4
- 6. Table created. SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL> SELECT * FROM new_table WHERE object_type = 'TABLE'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'NEW_TABLE' SQL> SET AUTOTRACE OFF SQL> CREATE INDEX idx_object_type ON new_table(object_type); Index created. SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL> SELECT * FROM new_table WHERE object_type = 'TABLE'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'NEW_TABLE' 2 1 INDEX (RANGE SCAN) OF 'IDX_OBJECT_TYPE' (NON-UNIQUE) CBO CBO có từ phiên bản Oracle7, CBO dựa vào “thông tin tổng hợp” được để ước tính chi phí của EP, EP tốt nhất là EP có chi phí ước tính nhỏ nhất. Oracle9i chỉ dùng CBO để tối ưu nếu đối tượng tham chiếu đến có thông tin mô tả. “Thông tin tổng hợp” trong ngữ cảnh này bao gồm: 1. Thông tin về hệ điều hành máy chủ Oracle: số CPU, tốc độ đọc ghi đĩa cứng, kích thước khối dữ liệu, cơ chế quản lý đĩa … 2. Thông tin mô tả các đối tượng dữ liệu: số dòng, cột và khối dữ liệu của Table, kích thước dòng, chiều cao và số nút lá của cây Index … 3. Thông tin về các thông số liên quan: optimizer_mode, db_file_multiblock_read_count, parallel_automatic_tuning …
- 7. Nếu cung cấp đầy đủ và chính xác các thông tin trên, trình tối ưu CBO có thể xác định được một EP tốt nhất. Tiếp theo ví dụ trong phần RBO, chúng ta dùng lệnh ANALYZE TABLE để thu thập thông tin của NEW_TABLE cho trình tối ưu: SQL> SET AUTOTRACE OFF SQL> @li NEW_TABLE indexes on table NEW_TABLE%: TABLE_NAME INDEX_TYPE INDEX_NAME -------------------- ---------- ------------------------------ NEW_TABLE NONUNIQUE IDX_OBJECT_TYPE SQL> ANALYZE TABLE new_table COMPUTE STATISTICS; Table analyzed. SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL>SELECT * FROM new_table WHERE object_type = 'TABLE'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=5 Card=2500 Bytes=107500) 1 0 TABLE ACCESS (FULL) OF 'NEW_TABLE' (Cost=5 Card=2500 Bytes=107500) Ta thấy kết quả của EP có một số điểm khác biệt so với thời điểm trước khi thu thập thông tin: 1. Có thêm thông tin về chi phí thực hiện của mỗi bước lệnh: (Cost=5 Card=2500 Bytes=107500), điều này chứng tỏ Oracle hiện đang dùng trình tối ưu CBO 2. CBO chọn phương thức truy cập TABLE ACCESS (FULL) mặc dù có tồn tại Index trên cột object_type.
- 8. Ph ụ l ục Gi ải nghĩa t ừ Bind-variable: kỹ thuật viết mã không gán giá trị cố định, kỹ thuật này giúp tăng tính sẵn sàng, hiệu năng và bảo mật cho hệ thống Oracle. Ví dụ: Mã không dùng Bind-Variable BEGIN UPDATE employees SET SALARY=SALARY + 100 WHERE employee_id = 100; END; Mã dùng Bind-Variable DECLARE bind_var NUMBER := 100; BEGIN UPDATE employees SET SALARY=SALARY + 100 WHERE employee_id = bind_var; END; Outer-table: từng dòng dữ liệu của Table này sẽ đối sánh với tất cả dòng của inner-table, còn gọi là driving-table, được đề cập đến trong phương pháp NESTED LOOP JOIN, thường đi chung với thuật ngữ inner-table Inner-table: tất cả dòng dữ liệu của Table này sẽ được đối sánh với từng dòng của outer-table.
- 9. Mã l ệnh Một số File mã lệnh tiện ích sử dụng trong bài viết: Tên mã l ệnh Mô t ả ch ức năng Liệt kê tất cả Index của bảng nhập vào select ui.table_name , decode(ui.index_type ,'NORMAL', ui.uniqueness ,ui.index_type) as index_type li.sql , ui.index_name from user_indexes ui where ui.table_name like upper('&1.%') order by ui.table_name , ui.uniqueness desc L ịch s ử thay đ ổi 1. 10/02/2009 - Giới thiệu bài viết 2. 20/02/2009 - Bổ sung phần "Công cụ tối ưu câu lệnh: SQL*Plus AUTOTRACE Tham kh ảo 1. Cách sử dụng "Bind Variable" khi lập trình Java với Oracle 2. Tài liệu chuẩn của Oracle Database 9i 3. Tài liệu khóa học Oracle Database 9i: SQL Tuning Mời các bạn đọc phần tiếp theo của chủ đề này: Ph ần 2 – T ối ưu câu l ệnh SQL có Table và có m ột đi ều ki ện
- 10. Ph ần 2: T ối ưu câu l ệnh SQL có m ột Table và có m ột đi ều ki ện Tiếp theo Phần 1: nền tảng cơ bản tối ưu câu lệnh Oracle SQL; giới thiệu các kiến thức cơ bản cần thiết để tối ưu câu lệnh SQL, chúng ta bắt đầu đi vào tìm hiểu kỹ thuật tối ưu câu lệnh cơ bản nhất, đó là tối ưu dựa vào Index, cụ thể là B*tree-Index, loại Index thường được dùng nhất. Chúng ta cũng cần lưu ý là Index chỉ giúp tăng tốc độ truy vấn trong một số trường hợp cụ thể, không phải bất kì trường hợp nào sử dụng Index cũng giúp tăng tốc độ. Trong thực tế, ta có thể xem phần mục lục của một cuốn sách giống như một cấu trúc Index; từ mục lục cuốn sách, bạn suy ra được số thứ tự trang sách chứa nội dung bạn cần tìm. Nếu sách vài trăm trang bạn có thể dựa vào mục lục để tìm được nội dung mong muốn một cách nhanh chóng, nhưng nếu sách chỉ vài trang thì tìm theo cách lật từng trang thì lại nhanh hơn. Cách tìm theo mục lục giống như phương thức truy cập TABLE ACCESS (BY INDEX ROWID), cách tìm lật từng trang sách giống như phương thức truy cập TABLE ACCESS (FULL). Phần hai này sẽ tập trung chủ yếu vào kỹ thuật tối ưu câu lệnh sử dụng Index, xem xét trường hợp nào Oracle sẽ dùng Index trong câu lệnh và ngược lại. Các ví dụ minh họa trong bài sẽ dùng Table tên CUSTOMERS của tài khoản SH, cấu trúc CUSTOMERS như sau: [oracle@localhost LABS]$ sid ORACLE_SID=ora9i [oracle@localhost LABS]$ [oracle@localhost LABS]$ alias sh alias sh='sqlplus "sh/sh"' [oracle@localhost LABS]$ sh SQL*Plus: Release 9.2.0.4.0 - Production on Mon Feb 16 08:56:20 2009 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production
- 11. SQL> DESC customers Name Null? Type ----------------------------------------------------------- -------- --------------- CUST_ID NOT NULL NUMBER CUST_FIRST_NAME NOT NULL VARCHAR2(20) CUST_LAST_NAME NOT NULL VARCHAR2(40) CUST_GENDER CHAR(1) CUST_YEAR_OF_BIRTH NUMBER(4) CUST_MARITAL_STATUS VARCHAR2(20) CUST_STREET_ADDRESS NOT NULL VARCHAR2(40) CUST_POSTAL_CODE NOT NULL VARCHAR2(10) CUST_CITY NOT NULL VARCHAR2(30) CUST_STATE_PROVINCE VARCHAR2(40) COUNTRY_ID NOT NULL CHAR(2) CUST_MAIN_PHONE_NUMBER VARCHAR2(25) CUST_INCOME_LEVEL VARCHAR2(30) CUST_CREDIT_LIMIT NUMBER CUST_EMAIL VARCHAR2(30) CUST_TOTAL VARCHAR2(14) SQL> Các tr ường h ợp ứng d ụng Index khi t ối ưu câu l ệnh SQL Oracle không dùng Index cho đi ều ki ện so sánh có toán t ử < >, != và NOT IN
- 12. Thường chúng ta nghĩ nếu cột dữ liệu trong mệnh đề điều kiện có Index, thì câu lệnh SQL sẽ sử dụng Index để truy vấn dữ liệu cho nhanh, tuy nhiên có nhiều trường hợp dù có Index nhưng Index vẫn không được. Trường hợp đầu tiên chúng ta xét đến là đối với các toán tử <>, != và NOT IN. Trước tiên, ta kiểm tra Table tên CUSTOMERS hiện đang có những Index nào: SQL> @li CUSTOMERS indexes on table CUSTOMERS%: TABLE_NAME INDEX_TYPE INDEX_NAME -------------------- ---------- ------------------------------ CUSTOMERS UNIQUE CUSTOMERS_PK NONUNIQUE CUST_CREDIT_LIMIT_IDX CUST_EMAIL_IDX CUST_LAST_NAME_IDX Dùng mã lệnh dai.sql xóa các nonprimary-key, khi đó CUSTOMERS chỉ còn primary-key tên CUSTOMERS_PK trên cột dữ liệu CUST_ID: SQL> @dai on which table: CUSTOMERS DROP INDEX CUSTOMERS_PK * ERROR at line 1: ORA-02429: cannot drop index used for enforcement of unique/primary key SQL> @li CUSTOMERS indexes on table CUSTOMERS%:
- 13. TABLE_NAME INDEX_TYPE INDEX_NAME -------------------- ---------- ------------------------------ CUSTOMERS UNIQUE CUSTOMERS_PK Xem cách trình tối ưu Oracle xử lý bốn câu lệnh sau: SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL> SELECT cust_first_name, cust_last_name FROM customers WHERE cust_id = 1030 / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS' 2 1 INDEX (UNIQUE SCAN) OF 'CUSTOMERS_PK' (UNIQUE) SQL> SELECT cust_first_name, cust_last_name FROM customers WHERE cust_id < 20000 / Execution Plan ----------------------------------------------------------
- 14. 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS' 2 1 INDEX (RANGE SCAN) OF 'CUSTOMERS_PK' (UNIQUE) SQL> SELECT cust_first_name, cust_last_name FROM customers WHERE cust_id between 70000 and 80000 / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS' 2 1 INDEX (RANGE SCAN) OF 'CUSTOMERS_PK' (UNIQUE) SQL> SELECT cust_first_name, cust_last_name FROM customers WHERE cust_id <> 1030 / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE
- 15. 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> Nhìn vào kết quả các câu lệnh, ta thấy trình tối ưu Oracle đang được chỉ định giá trị là Optimizer=CHOOSE, nghĩa là sẽ chọn CBO nếu CUSTOMERS có thông tin mô tả và chọn RBO nếu không có. Mặc định CUSTOMERS không có thông tin mô tả, vì vậy trong trường hợp này trình tối ưu sẽ dùng phương pháp RBO để xác định EP cho các câu lệnh. Như tìm hiểu trong phần trước, RBO sử dụng lược đồ luật phân hạng để chọn EP tốt nhất, ưu tiên chọn phương thức truy cập dữ liệu theo Index hơn là phương thức duyệt từng dòng dữ liệu của Table. Nhưng theo ví dụ trên, ta thấy RBO chỉ dùng Index cho 3 câu lệnh đầu tiên, không dùng Index cho câu lệnh cuối cùng. Để ý thì ta thấy ba câu lệnh đầu sử dụng toán tử so sánh =, < và BETWEEN AND, các toán tử này đều có khuynh hướng giới hạn tập dữ liệu trả về, còn câu lệnh thứ tư thì sử dụng toán tử <>, toán tử này luôn trả về tập kết quả lớn. Như vậy, Oracle RBO ứng xử như vậy là hợp lý, dùng Index cho câu lệnh sử dụng toán tử so sánh có khuynh hướng trả về ít dữ liệu và không dùng Index cho trường hợp câu lệnh có toán tử so sánh trả về nhiều dữ liệu. RBO sẽ ứng xử tương tự như <> cho các toán tử != và NOT IN. Oracle không dùng Index cho c ột d ữ li ệu k ết h ợp v ới b ất kì thành ph ần khác Dù cột dữ liệu có Index, nhưng nếu ta kết hợp nó với bất kì thành phần nào khác, chẳng hạn như một giá trị, một biểu thức thì Index trên cột dữ liệu đó sẽ không được trình tối ưu Oracle ứng dùng. Xem xét các ví dụ dưới đây: SQL> SELECT * 2 FROM customers 3 WHERE cust_id + 1 = 100; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> SELECT * 2 FROM customers 3 WHERE TO_NUMBER(cust_id) = 100;
- 16. Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> SELECT * 2 FROM customers 3 WHERE cust_id + null = 100; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> SELECT * 2 FROM customers 3 WHERE cust_id = 100; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS'
- 17. 2 1 INDEX (UNIQUE SCAN) OF 'CUSTOMERS_PK' (UNIQUE) SQL> Ta thấy ba trường hợp đầu tiên, dù cột dữ liệu kết hợp với giá trị NULL , giá trị rỗng, cũng khiến Oracle RBO không ứng dụng Index cho câu lệnh. Đối với trường hợp TO_NUMBER(cust_id) thì do hàm TO_NUMBER kết buộc với cột CUST_ID nên làm mất tác dụng của Index, tuy nhiên chúng ta có thể sử dụng kỹ thuật function-based Index; tạo Index trực tiếp trên hàm kết buộc vào cột dữ liệu, để thực hiện phương thức truy cập dữ liệu theo Index mà không cần bỏ hàm TO_NUMBER(). SQL> CREATE INDEX cust_id_tonumber_idx ON customers(to_number(cust_id)); Index created. SQL> @li indexes on table CUSTOMERS%: TABLE_NAME INDEX_TYPE INDEX_NAME -------------------- ---------- ------------------------------ CUSTOMERS UNIQUE CUSTOMERS_PK NONUNIQUE CUST_CREDIT_LIMIT_IDX FUNCTION-B CUST_ID_TONUMBER_IDX ASED NORMA L SQL> SET AUTOTRACE TRACEONLY EXPLAIN
- 18. SQL> SELECT * 2 FROM customers 3 WHERE to_number(cust_id) = 100; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> ANALYZE TABLE customers COMPUTE STATISTICS; Table analyzed. SQL> SELECT * 2 FROM customers 3 WHERE to_number(cust_id) = 100; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=137) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS' (Cost=2 Card=1 Bytes=137) 2 1 INDEX (RANGE SCAN) OF 'CUST_ID_TONUMBER_IDX' (NON-UNIQUE) (Cost=1 Card=1)
- 19. SQL> Như ta thấy, chỉ trình tối ưu CBO mới hiểu kỹ thuật Function-based Index, RBO không hiểu. Vì vậy, để trình tối ưu Oracle tự động dùng CBO thì chúng ta cần thu thập thông tin mô tả cho CUSTOMERS. Lưu ý thêm về cách thu thập thông tin mô tả cho Table, chúng ta sử dụng cú pháp lệnh ANALYZE TABLE vì lệnh này đơn giản, dễ hiểu và cú pháp trong sáng, đáp ứng đủ cho các minh họa của chúng ta. Khi ứng dụng thu thập thông tin cho hệ thống Oracle thực tế, các bạn nên dùng gói lệnh DBMS_STATS thì hiệu quả hơn. Oracle Index và toán t ử LIKE Để minh họa cho ý này, chúng ta sẽ tạo thêm một Index trên cột dữ liệu CUST_LAST_NAME theo mã lệnh ci.sql: SQL> @ci on which table : CUSTOMERS on which column(s): cust_last_name Creating index on: CUSTOMERS cust_last_name Enter value for index_name: cust_last_name_idx SQL> @li CUSTOMERS indexes on table CUSTOMERS%: TABLE_NAME INDEX_TYPE INDEX_NAME -------------------- ---------- ------------------------------ CUSTOMERS UNIQUE CUSTOMERS_PK NONUNIQUE CUST_CREDIT_LIMIT_IDX FUNCTION-B CUST_ID_TONUMBER_IDX ASED NORMA L
- 20. NONUNIQUE CUST_LAST_NAME_IDX Tiếp theo, chúng ta xét ví dụ sau: SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL> SELECT cust_id 2 FROM customers 3 WHERE cust_last_name LIKE 'S%' / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'CUSTOMERS' 2 1 INDEX (RANGE SCAN) OF 'CUST_LAST_NAME_IDX' (NON-UNIQUE) SQL> SELECT cust_last_name 2 FROM customers 3 WHERE cust_last_name LIKE '%S%’ / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS'
- 21. SQL> SELECT cust_id 2 FROM customers 3 WHERE cust_last_name LIKE '%S' / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> Như vậy, trình tối ưu Oracle RBO chỉ ứng dụng Index cho toán tử LIKE nếu giá trị so sánh không có kí tự đặc biệt % ở đầu. Chúng ta xét tiếp ví dụ sau: SQL> SELECT cust_last_name 2 FROM customers 3 WHERE cust_last_name like 'S%' / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 INDEX (RANGE SCAN) OF 'CUST_LAST_NAME_IDX' (NON-UNIQUE) SQL>
- 22. Các bạn thấy điểm khác biệt ở đây chứ ? EP không có bước lệnh TABLE ACCESS (BY INDEX ROWID) như bình thường, mà chỉ có INDEX (RANGE SCAN). Nguyên nhân do cột dữ liệu kết quả trả về chỉ có CUST_LAST_NAME, mà dữ liệu này chính là giá trị khóa của Index tên CUST_LAST_NAME_IDX, vì vậy Oracle chỉ cần duyệt cây Index là có thể lấy được kết quả mong muốn, không cần tốn thêm chi phí duyệt Table như bình thường. Tiếp tục với ví dụ sau: SQL> SELECT cust_last_name 2 FROM customers 3 WHERE cust_id LIKE '7%' / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> Các bạn có đoán ra được lý do tại sao trình tối ưu Oracle RBO không ứng dùng Index trên cột dữ liệu CUST_ID ? Do CUST_ID là cột dữ liệu kiểu số, nhưng câu lệnh lại so sánh với một giá trị chuỗi ‘7%’, nên trong trường hợp này Oracle tự động ngầm định chuyển đổi kiểu cho mệnh đề điều kiện thành như sau: SQL> SELECT cust_last_name 2 FROM customers 3 WHERE TO_CHAR(cust_id) LIKE '7%' Do cột dữ liệu CUST_ID bị kết buộc với hàm TO_CHAR() khi so sánh, nên bị mất tác dụng Index. Tóm tắt những ý chúng ta đã tìm hiểu được trong phần này: 1. Oracle chỉ ứng dụng Index cho toán tử LIKE khi giá trị so sánh không có kí tự % ở đầu 2. Nếu kết quả dữ liệu của câu lệnh có thể tìm thấy đủ trong Index, thì Oracle chỉ cần duyệt cây Index để lấy kết quả trả về, mà không cần duyệt trên Table. 3. Nếu cột dữ liệu trong mệnh đề điểu kiện so sánh với một giá trị khác kiểu, Oracle tự động chuyển đổi kiểu ngầm định cho cột dữ liệu đó, điều này khiến Index không được ứng dụng.
- 23. Oracle Index và giá tr ị NULL Theo kiến trúc cơ sở dữ liệu Oracle, cấu trúc cây Index ,B*tree-Index, không lưu thông tin về dòng dữ liệu của Table có giá trị khóa là NULL. Vậy theo bạn, Oracle sẽ ứng xử thế nào khi so sánh điều kiện trên cột dữ liệu có giá trị NULL ? chúng ta sẽ tìm hiểu ý này ngay trong phần dưới đây. Để chuẩn bị cho phần này, chúng ta cập nhật một số giá trị của cột dữ liệu CUST_EMAIL về NULL và tạo Index tên CUST_EMAIL_IDX trên cột này. SQL> SET AUTOTRACE OFF SQL> UPDATE customers 2 SET cust_email = null 3 WHERE rownum < 101 / 100 rows updated. SQL> COMMIT; Commit complete. SQL> @ci on which table : CUSTOMERS on which column(s): CUST_EMAIL Creating index on: CUSTOMERS CUST_EMAIL Enter value for index_name: CUST_EMAIL_IDX SQL> SET AUTOTRACE TRACEONLY EXPLAIN
- 24. SQL> SELECT cust_email 2 FROM customers 3 WHERE cust_email IS NULL / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS' SQL> Theo ví dụ trên, Oracle đã không dùng Index dù cột CUST_EMAIL có Index. Giải thích cho cách ứng xử này là do B*tree-Index không lưu thông tin về dòng dữ liệu chứa giá trị khóa là NULL, vì vậy Oracle phải thực hiện quét từng dòng dữ liệu của Table để tìm được các CUST_EMAIL có giá trị NULL. Vậy các bạn thử xem tiếp ví dụ sau, tại sao Oracle vẫn không dùng Index ? SQL> SET AUTOTRACE TRACEONLY EXPLAIN SQL> SELECT cust_id 2 FROM customers 3* WHERE cust_email IS NOT NULL SQL> / Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (FULL) OF 'CUSTOMERS'
- 25. SQL> Nếu Oracle B*tree-Index không lưu giá trị NULL, vậy khi tìm giá trị khác NULL thì theo suy luận bình thường Oracle phải dùng Index trong trường hợp này ? Không như vậy, Oracle “nghĩ” rằng điều kiện IS NOT NULL sẽ trả về tập kết quả lớn, nếu dùng Index sẽ không hiệu quả, nên Oracle chọn phương thức truy cập dữ liệu TABLE ACCESS (FULL) sẽ hiệu quả hơn. Ph ụ l ục Mã l ệnh Một số File mã lệnh tiện ích sử dụng trong bài viết: Tên mã l ệnh Mô t ả ch ức năng Liệt kê tất cả Index của bảng nhập vào select ui.table_name , decode(ui.index_type ,'NORMAL', ui.uniqueness li.sql ,ui.index_type) as index_type , ui.index_name from user_indexes ui where ui.table_name like upper('&1.%') order by ui.table_name , ui.uniqueness desc Xóa hết tất cả non-primary key Index trên một cột dữ liệu nhập vào của một Table accept TABLE_NAME prompt " on which table: " set termout off store set saved_settings replace set heading off verify off autotrace off feedback off spool doit.sql select 'DROP INDEX '||ui.index_name||';' dai.sql from user_indexes ui where table_name like upper('&TABLE_NAME.%') / spool off set termout on @doit @saved_settings undef TABLE_NAME set termout on ci.sql Tạo mới một Non-Unique Index trên một cột dữ liệu nhập vào của một Table accept TABLE_NAME prompt " on which table :"
- 26. |accept COLUMN_NAME prompt " on which column(s): " set termout off store set saved_settings replace set heading off feedback off autotrace off set verify off termout on select 'Creating index on: ' , '&&TABLE_NAME' , '&&COLUMN_NAME' FROM DUAL / create index &INDEX_NAME on &TABLE_NAME(&COLUMN_NAME) / @saved_settings set termout on undef INDEX_NAME undef TABLE_NAME undef COLUMN_NAME